
Authors: Ravi Raju, Swayambhoo Jain, Bo Li, Jonathan Li, Urmish Thakkar
Abstract: Large Language Models (LLMs) have revolutionized the landscape of machine
learning, yet current benchmarks often fall short in capturing the diverse
behavior of these models in real-world applications. A benchmark’s usefulness
is determined by its ability to clearly differentiate between models of varying
capabilities (separability) and closely align with human preferences. Existing
frameworks like Alpaca-Eval 2.0 LC
\cite{dubois2024lengthcontrolledalpacaevalsimpleway} and Arena-Hard v0.1
\cite{li2024crowdsourced} are limited by their focus on general-purpose queries
and lack of diversity across domains such as law, medicine, and multilingual
contexts. In this paper, we address these limitations by introducing a novel
data pipeline that curates diverse, domain-specific evaluation sets tailored
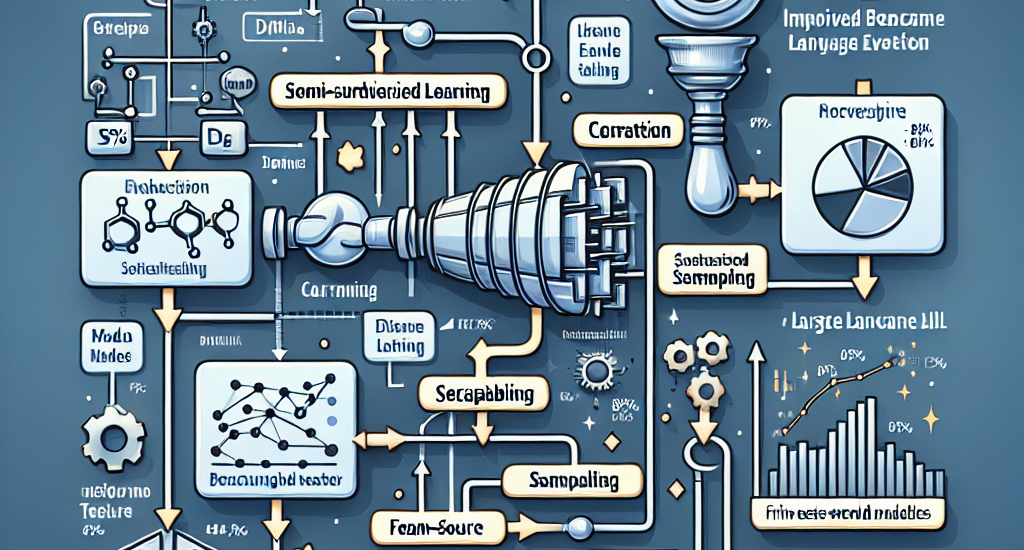
for LLM-as-a-Judge frameworks. Our approach leverages a combination of manual
curation, semi-supervised learning to generate clusters, and stratified
sampling to ensure balanced representation across a wide range of domains and
languages. The resulting evaluation set, which includes 1573 samples across 14
categories, demonstrates high separability (84\%) across ten top-ranked models,
and agreement (84\%) with Chatbot Arena and (0.915) Spearman correlation. The
agreement values are 9\% better than Arena Hard and 20\% better than AlpacaEval
2.0 LC, while the Spearman coefficient is 0.7 more than the next best
benchmark, showcasing a significant improvement in the usefulness of the
benchmark. We further provide an open-source evaluation tool that enables
fine-grained analysis of model performance across user-defined categories,
offering valuable insights for practitioners. This work contributes to the
ongoing effort to enhance the transparency, diversity, and effectiveness of LLM
evaluation methodologies.
Source: http://arxiv.org/abs/2408.08808v1



